文字型のところで学習したように、C 言語では文字と文字列は全く違った扱い をする。日本語の漢字なども文字列として扱うが、では文字列はどのようにして 扱われるのであろうか。
実は、我々は既に文字列を扱っている。printf() で "this" など
と使っているのが文字列なのである。では、この文字列はどのような仕組みになって
いるのかというと、文字列としてプログラム中で指定したものは必ずメモリ中の
どこかに存在するようになっている。しかし、メモリ中のどこかはこのままでは
分からない。今までの使い方では、場所がどこか分からなくても一回しか使わない
ので問題はなかった。同じ文字列を何度も扱ったり、変更したりするにはどうすれば
良いのであろうか。
例2
char *s = "this";
printf("address of string is %u\n", s);
printf("letter is %s\n", s);
|
この例では、まず、最初に文字型のポインタ変数 s を宣言し、同時に
初期化を行っているが、この初期化方法の意味をまず解説しよう。プログラム中に
書かれた文字列は必ずメモリ中の何処かに存在するようになる。しかし、そのまま
では何処にあるかは分からない。そこで、C 言語では文字列はアドレスを持つように
定義されているのである。従って、最初の宣言の右辺はアドレスである。それを、
初期化によって、ポインタ変数 s にセットしている訳である。しかし、文字列の
アドレスといっても、この場合は "this" という 4 個の文字からなっているので、
全ての文字へのアドレスを覚えているのではなく、先頭の文字へのアドレスを持たせて
いる。この場合、2 番目以降の文字は次々にアドレスを変化させて見て行く事に
なるのだが、何処で終わるかという事が分からなければ果てしなく続く事になって
しまうので、C 言語では、文字列の終わりを表す印として '\0' という目印
を最後に書き込む決まり になっている。
従って、4 個の文字だけがメモリ中にあるのではなく、実は 5 個の文字がメモリ中
にあることになる。
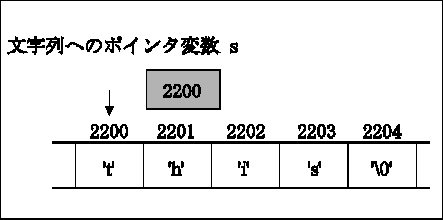
このようにして、
ポインタ変数 s に入っているアドレスは、文字 't' へのアドレスになっている。
ちなみに、printf() の書式制御に %s を指定し、文字列へのアドレス
を渡すと文字列を出力出来る。この状況を図に示したのが上図である。
例3
char *s = "this";
printf("string is %s\n", s);
|
printf("%s", 文字列へのアドレス);
|