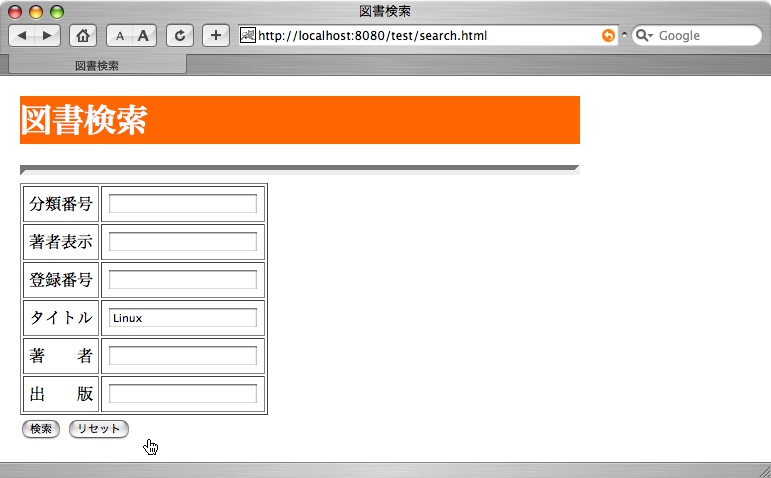
ここでは、JDBCを使ったServletプログラミングについて解説しましょう。ここで紹介するサンプルプログラムは、図書検索アプリケーションです。まず、図9.1[入力画面]に、調べたい本のタイトル、著者名などを入力して、検索ボタンを押します。
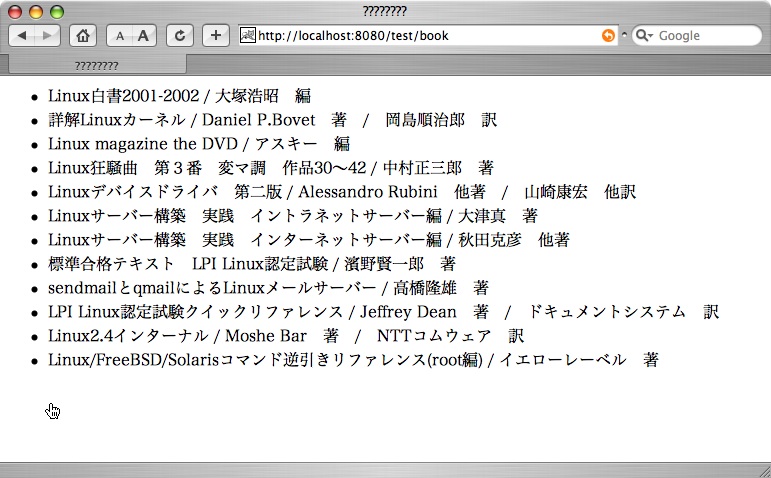
入力されたパラメータの情報はServletが受け取り、Servletはデータベースから検索を行います。そして、図9.2[検索結果表示画面]のように検索結果を出力します。
まずServletをご覧ください。
import java.io.PrintWriter;
import java.io.IOException;
import java.sql.DriverManager;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class SimpleBookSearchServlet extends HttpServlet {
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
doIt(request, response);
}
public void doPost(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
doIt(request, response);
}
private void doIt(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
request.setCharacterEncoding("Shift_JIS");
String ndc = request.getParameter("ndc");
String tyosya_hyouji = request.getParameter("tyosya_hyouji");
String id = request.getParameter("id");
String title = request.getParameter("title");
String author = request.getParameter("author");
String publisher = request.getParameter("publisher");
try {
Class.forName("org.hsqldb.jdbcDriver");
String url = "jdbc:hsqldb:hsql://localhost";
Connection con = DriverManager.getConnection(url, "sa", "");
String selectStatement =
"select * " +
"from books where ndc like ? " +
"and tyosya_hyouji like ? " +
"and id like ? " +
"and title like ? " +
"and author like ? " +
"and publisher like ? ";
PreparedStatement prepStmt =
con.prepareStatement(selectStatement);
prepStmt.setString(1, appendPercent(ndc));
prepStmt.setString(2, appendPercent(tyosya_hyouji));
prepStmt.setString(3, appendPercent(id));
prepStmt.setString(4, appendPercent(title));
prepStmt.setString(5, appendPercent(author));
prepStmt.setString(6, appendPercent(publisher));
response.setContentType("text/html; charset=Shift_JIS");
PrintWriter out = response.getWriter();
out.println("<html>");
out.println("<head>");
out.println("<title>検索結果</title>");
out.println("</head>");
out.println("<body>");
out.println("<ul>");
ResultSet rs = prepStmt.executeQuery();
while (rs.next()) {
out.println("<li>");
out.print(rs.getString("title"));
out.print(" / ");
out.print(rs.getString("author"));
out.println("</li>");
}
rs.close();
prepStmt.close();
con.close();
out.println("</ul>");
out.println("</body>");
out.println("</html>");
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
private String appendPercent(String from) {
StringBuffer to = new StringBuffer();
to.append("%");
to.append(from);
to.append("%");
return new String(to);
}
}
このプログラムの中心部分はdoItメソッドです。このメソッドの中では、次のような処理が行われています。
これらのうち、HTMLの生成部分については、doItメソッドの各所にちらばっており、プログラム全体のロジックがわかりにくくなっています。
では、このdoItメソッドをわかりやすく分割して書いてみましょう。
今回のような、データベースからデータを検索するようなWebアプリケーションの場合、データベースからの検索結果1件分を1つのJavaBeansに格納し、複数の検索結果(つまり複数のJavaBeans)をjava.util.Listなどのコレクションでまとめるのが普通です。
JavaBeansを作成するときには、検索結果の項目それぞれを、JavaBeansのプロパティで管理するようにします。
まずはJavaBeansを見てみましょう。
package jp.ac.wakhok.library;
import java.io.Serializable;
public class BookData implements Serializable {
private String ndc = "";
private String tyosya_hyouji = "";
private int id = 0;
private String title = "";
private String author = "";
private String publisher = "";
public String getNdc() {
return ndc;
}
public void setNdc(String ndc) {
this.ndc = ndc;
}
public String getTyosya_hyouji() {
return tyosya_hyouji;
}
public void setTyosya_hyouji(String tyosya_hyouji) {
this.tyosya_hyouji = tyosya_hyouji;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getPublisher() {
return publisher;
}
public void setPublisher(String publisher) {
this.publisher = publisher;
}
}
なぜ検索結果をJavaBeansで管理するのが良いのでしょうか?次のような理由があります。
続いて、Servletのプログラムを見てみましょう。
データベースからの検索とHTMLの生成がそれぞれ別のメソッドで処理されています。そして、これらのメソッドでデータの受け渡しに使われているのがBookDataというJavaBeansをまとめているjava.util.List型のオブジェクトです。
import java.io.PrintWriter;
import java.io.IOException;
import java.util.List;
import java.util.ArrayList;
import java.sql.DriverManager;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import jp.ac.wakhok.library.BookData;
public class BookSearchServlet extends HttpServlet {
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
doIt(request, response);
}
public void doPost(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
doIt(request, response);
}
private void doIt(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
request.setCharacterEncoding("Shift_JIS");
String ndc = request.getParameter("ndc");
String tyosya_hyouji = request.getParameter("tyosya_hyouji");
String id = request.getParameter("id");
String title = request.getParameter("title");
String author = request.getParameter("author");
String publisher = request.getParameter("publisher");
List<BookData> list =
search(ndc, tyosya_hyouji, id, title, author, publisher);
printBookData(response, list);
}
private List<BookData> search(String ndc, String tyosya_hyouji,
String id, String title,
String author, String publisher) {
List<BookData> list = new ArrayList<BookData>();
try {
Class.forName("org.hsqldb.jdbcDriver");
String url = "jdbc:hsqldb:hsql://localhost";
Connection con = DriverManager.getConnection(url, "sa", "");
String selectStatement =
"select * " +
"from books where ndc like ? " +
"and tyosya_hyouji like ? " +
"and id like ? " +
"and title like ? " +
"and author like ? " +
"and publisher like ? ";
PreparedStatement prepStmt =
con.prepareStatement(selectStatement);
prepStmt.setString(1, appendPercent(ndc));
prepStmt.setString(2, appendPercent(tyosya_hyouji));
prepStmt.setString(3, appendPercent(id));
prepStmt.setString(4, appendPercent(title));
prepStmt.setString(5, appendPercent(author));
prepStmt.setString(6, appendPercent(publisher));
ResultSet rs = prepStmt.executeQuery();
while (rs.next()) {
BookData book = new BookData();
book.setNdc(rs.getString("ndc"));
book.setTyosya_hyouji(rs.getString("tyosya_hyouji"));
book.setId(rs.getInt("id"));
book.setTitle(rs.getString("title"));
book.setAuthor(rs.getString("author"));
book.setPublisher(rs.getString("publisher"));
list.add(book);
}
rs.close();
prepStmt.close();
con.close();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
return list;
}
private String appendPercent(String from) {
StringBuffer to = new StringBuffer();
to.append("%");
to.append(from);
to.append("%");
return new String(to);
}
private void printBookData(
HttpServletResponse response, List<BookData> list)
throws ServletException, IOException {
response.setContentType("text/html; charset=Shift_JIS");
PrintWriter out = response.getWriter();
out.println("<html>");
out.println("<head>");
out.println("<title>検索結果</title>");
out.println("</head>");
out.println("<body>");
out.println("<ul>");
for (BookData book: list) {
out.println("<li>");
out.print(book.getTitle());
out.print(" / ");
out.print(book.getAuthor());
out.println("</li>");
}
out.println("</ul>");
out.println("</body>");
out.println("</html>");
}
}
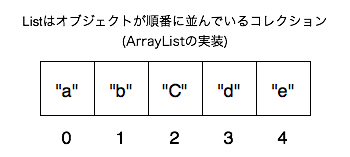
Listは、図9.3[List]のような、オブジェクトが順番に並んだコレクションです。
java.util.Listはインターフェースであり、これを実装したクラスには
などがあります。これらのクラスはそれぞれ実装方法が異なっており、状況に応じて使い分けることができます。
リスト4-1は、ファイルの内容を1行ずつArrayListクラスのインスタンスに格納するメソッドです。
// リスト 4-1
1 public List<String> readFile(String fileName) {
2 List<String> list = new ArrayList<String>();
3 try {
4 FileReader file_reader = new FileReader(fileName);
5 BufferedReader buffered_reader = new BufferedReader(file_reader);
6 String line;
7 while ((line = buffered_reader.readLine()) != null) {
8 list.add(line);
9 }
10 buffered_reader.close();
11 file_reader.close();
12 } catch (FileNotFoundException e) {
13 e.printStackTrace();
14 } catch (IOException e) {
15 e.printStackTrace();
16 }
17 return list;
18 }
リスト4-1では、2行目で
List<String> list = new ArrayList<String>();
のように、ArrayListクラスのインスタンスを生成しています。このreadFileメソッドでは、ファイルの内容を1行ずつ取りだしています。取り出したデータは、8行目でListインターフェースのメソッドList#add(String)を使い、オブジェクトlistに追加します。つまりreadFileメソッドでは、ファイルのすべての行をlistに格納し、最後にこのlistを返しているのです。
リスト4-1の2行目について、もう少し解説を加えましょう。
List<String> list = new ArrayList<String>();
普通なら、次のように書くところです。
ArrayList<String> list = new ArrayList<String>();
しかし、先に述べたように、ArrayListはListインタフェースを実装しています。
public class ArrayList implements List {
……
}
この場合、ArrayList型のインスタンスは、List型も持っていることになります。よって、次のように記述できます。
List<String> list = new ArrayList<String>();
では、ArrayListの代わりに後述するLinkedListを使うようにしたとしましょう。ArrayListと同様に、LinkedListもListインタフェースを実装しているので、次のように書けばよいのです。
List<String> list = new LinkedList<String>();
ArrayListを使ったプログラムをJ2SE 1.4で書くと、次のようなパターンになります。
List l = new ArrayList();
l.add("1000");
……
String str = (String)list.get(0);
addメソッドではString型である"1000"というオブジェクトを追加しています。このメソッドの引数はObject型です。JavaのすべてのクラスはObject型を継承しているので、つまりaddメソッドにはどのような型のオブジェクトでも追加できるということになります。
最後の行のように、getメソッドでオブジェクトを取得しています。このメソッドの返値もObject型なので、(String)のようにキャストを行っています。
ところが、この方式では、listインスタンスにどのような型のオブジェクトでも追加できてしまいます。そのため、String型以外のオブジェクトがlistに追加されていると、最終行のキャストのところでエラーになってしまいます。
このエラーは、コンパイル時ではなく、実行時に検出されることになります。実行時エラーの原因追及は、なかなかやっかいな作業です。
こうしたエラーを防ぐために、J2SE 5.0からはGenericsという機能が追加されました。
Genericsを使うと、次のようにプログラムを記述できます。
List<String> list = new ArrayList<String>();
list.add("1000");
……
String str = list.get(0);
1行目の2カ所で登場する"<String>"の部分がGenericsです。この行では、Listで管理するオブジェクトをString型に限定しています。それ以外の型のオブジェクトが追加されると、エラーになります。つまり、listインスタンスに含まれるのはString型だけであることが保証されるのです。このおかげで、最終行のgetメソッドではキャストが必要なくなります。
Genericsを使うことによって、コレクションの定義が明確になり、実行時エラーが起こる可能性をかなり減らすことができます。
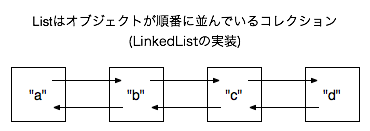
Listインターフェースを実装したクラスのなかでは、java.util.ArrayListがよく使われています。しかし、ArrayListのインスタンスに対して、頻繁にオブジェクトの挿入や削除を行うなら、ArrayListではなくjava.util.LinkedListを使った方が良いでしょう。このクラスは図9.4[LinkedList]のように「ダブルリンクトリスト」という手法を使って実装されており、オブジェクトの挿入や削除が頻繁に起こる場合、効率が良くなるからです。
リスト4-1でjava.util.ArrayListをjava.util.LinkedListに変えるには、2行目の部分を
List<String> list = new LinkedList<String>();
とするだけです。他の部分は変更しなくても構いません。
Javaはマルチスレッドに対応したプログラミング言語なので、複数のスレッドを同時に動作させることが可能になります。
1つのオブジェクトに、2つのスレッドがアクセスするとしましょう。1つのスレッドでは、そのオブジェクトを削除しようとしています。別のスレッドでは、オブジェクトを内容を取得しようとしています。この2つのスレッドが同時に実行され、オブジェクトへのアクセスが同時に行われた場合、矛盾が生じる可能性があります。
そこで、ひとつのオブジェクトに、同時にはアクセスできないようにする工夫が必要です。これを「同期化」と言います。ただし、同期化させるとプログラムの処理が遅くなります。
ArrayListやLinkedListは同期化されていないので、マルチスレッドで使うときには動作が保証されません。同期化するには、リスト4-2のようにjava.util.CollectionsクラスのメソッドCollections#synchronizedList(List)を使います。
// リスト 4-2
List<String> newList = Collections.synchronizedList(list);
java.util.Vectorは、Java 2 SDKが登場する前から存在しており、ArrayListによく似た機能を持っています。ArrayListとは違って、同期化もされています。Java 2 SDK以降でのVectorは、java.util.Listインターフェースを実装するように変更されました。
コレクションに含まれているそれぞれのオブジェクトに対して、繰り返しの処理をするには、java.util.Iteratorを使います。図9.5[Iterator]のようなイメージになります。
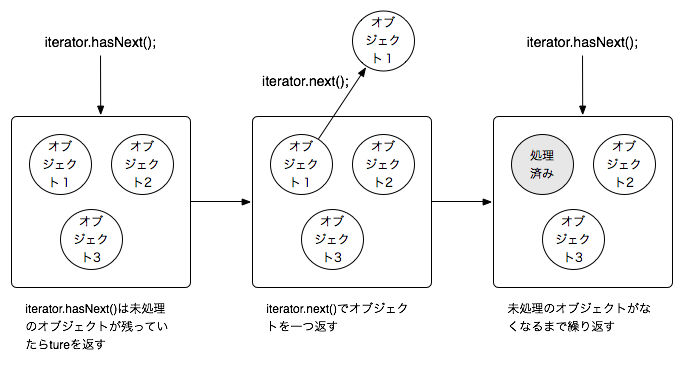
まずは、Iteratorを使ったサンプルを見てみましょう。リスト4-7は、リスト4-1のプログラムに、List型のオブジェクトに格納されたファイルの中身をIteratorを使って出力する機能を加えたものです。
// リスト 4-7
1 import java.util.List;
2 import java.util.ArrayList;
3 import java.util.Iterator;
4 import java.io.FileReader;
5 import java.io.BufferedReader;
6 import java.io.FileNotFoundException;
7 import java.io.IOException;
8
9 public class IteratorTest {
10
11 public List<String> readFile(String fileName) {
12 List<String> list = new ArrayList<String>();
13 try {
14 FileReader file_reader = new FileReader(fileName);
15 BufferedReader buffered_reader = new BufferedReader(file_reader);
16 String line;
17 while ((line = buffered_reader.readLine()) != null) {
18 list.add(line);
19 }
20 } catch (FileNotFoundException fnfe) {
21 fnfe.printStackTrace();
22 } catch (IOException ioe) {
23 ioe.printStackTrace();
24 }
25 return list;
26 }
27
28 public static void main(String[] argv) {
29 IteratorTest test = new IteratorTest();
30 List<String> list = test.readFile(argv[0]);
31 Iterator<String> iterator = list.iterator();
32 while (iterator.hasNext()) {
33 String value = iterator.next();
34 System.out.println(value);
35 }
36 }
37 }
// リスト 4-7 の実行例 C:\Home> java IteratorTest sample.txt java.util.List java.util.Set java.util.Map java.util.SortedSet java.util.SortedMap java.util.Date java.text.DateFormat org.w3c.dom.Node gnu.regexp.RE jp.ac.wakhok.tomoharu.CSVLine
まず31行目でIteratorを取り出します。32行目でまだ処理をしていないオブジェクトが残っているかどうかチェックし、33行目でオブジェクトを1つ取り出しています。
このようにIteratorを使えば、繰り返しのループ処理を簡潔に書けるのです。
また、Iteratorとよく似た機能を持つ、java.util.Enumerationがあります。JDK1.1まではjava.util.Iteratorはなかったので、VectorやHashtableに含まれているオブジェクトの繰り返し処理に使われます。
J2SE 5.0からは、for文を使ってコレクションを操作することも容易になりました。
次のようなパターンで、コレクションや配列に含まれる要素を繰り返し処理することができます。
for (要素の型 要素名: コレクション or 配列) {
……
}
先のIteratorの例は、for文を使って次のようにかけます。Iteratorを使うよりもプログラムが単純になっていることがわかりますね。
for (String value: list) {
System.out.println(value);
}