
プログラミングでは、データを集め、集められたデータについて何らかの操作を行うことがよくあります。Javaには、こうしたことに対応するため、「コレクション・フレームワーク」という機能があります。「コレクション」とは、オブジェクトをまとめているオブジェクトです。
コレクション・フレームワークには、次のような機能があります。
コレクションには、6つの基本的なインターフェースと、その実装クラスがあります。
ここでは、List, Set, Mapの3つのインターフェースを見てみましょう。
Listは、図C.1[List]のような、オブジェクトが順番に並んだコレクションです。
java.util.Listはインターフェースであり、これを実装したクラスには
などがあります。これらのクラスはそれぞれ実装方法が異なっており、状況に応じて使い分けることができます。
リスト4-1は、ファイルの内容を1行ずつArrayListクラスのインスタンスに格納するメソッドです。
// リスト 4-1
1 public List readFile(String fileName) {
2 List list = new ArrayList();
3 try {
4 FileReader file_reader = new FileReader(fileName);
5 BufferedReader buffered_reader = new BufferedReader(file_reader);
6 String line;
7 while ((line = buffered_reader.readLine()) != null) {
8 list.add(line);
9 }
10 buffered_reader.close();
11 file_reader.close();
12 } catch (FileNotFoundException e) {
13 e.printStackTrace();
14 } catch (IOException e) {
15 e.printStackTrace();
16 }
17 return list;
18 }
リスト4-1では、2行目で
List list = new ArrayList();
のように、ArrayListクラスのインスタンスを生成しています。インスタンスの型がListなのは、ArrayListクラスがListインターフェースを実装しているからです。このreadFileメソッドでは、ファイルの内容を1行ずつ取りだしています。取り出したデータは、8行目でListインターフェースのメソッドList#add(String)を使い、オブジェクトlistに追加します。つまりreadFileメソッドでは、ファイルのすべての行をlistに格納し、最後にこのlistを返しているのです。
Listインターフェースを実装したクラスのなかでは、java.util.ArrayListがよく使われています。しかし、ArrayListのインスタンスに対して、頻繁にオブジェクトの挿入や削除を行うなら、ArrayListではなくjava.util.LinkedListを使った方が良いでしょう。このクラスは「ダブルリンクトリスト」という手法を使って実装されており、オブジェクトの挿入や削除が頻繁に起こる場合、効率が良くなるからです。
リスト4-1でjava.util.ArrayListをjava.util.LinkedListに変えるには、2行目の部分を
List list = new LinkedList();
とするだけです。他の部分は変更しなくても構いません。2行目のコンストラクタで生成されるインスタンスは、List型であるからです。
ArrayListやLinkedListは同期化されていないので、マルチスレッドで使うときには動作が保証されません。同期化するには、リスト4-2のようにjava.util.CollectionsクラスのメソッドCollections#synchronizedList(List)を使います。
// リスト 4-2
List newList = Collections.synchronizedList(list);
java.util.Vectorは、Java 2 SDKが登場する前から存在しており、ArrayListによく似た機能を持っています。ArrayListとは違って、同期化もされています。Java 2 SDK以降でのVectorは、java.util.Listインターフェースを実装するように変更されました。
Setは、オブジェクトの重複がないコレクションです。数学での「集合」をモデル化しています。
java.util.Setはインターフェースであり、これを実装したクラスに
があります。
リスト4-3は、HashSetクラスのインスタンスにあらかじめオブジェクトを登録しておき、指定したオブジェクトがコレクションに存在するかどうか確かめるプログラムです。
// リスト 4-3
1 import java.util.Set;
2 import java.util.HashSet;
3
4 public class SetTest {
5 private Set set;
6
7 public SetTest() {
8 set = new HashSet();
9
10 // あらかじめデータを登録する
11 set.add("10000");
12 set.add("20000");
13 set.add("30000");
14 }
15
16 public void check(String number) {
17 if (set.contains(number)) {
18 System.out.print(number);
19 System.out.println("はあります");
20 } else {
21 System.out.print(number);
22 System.out.println("はありません");
23 }
24 }
25
26 public static void main(String[] argv) {
27 SetTest test = new SetTest();
28 test.check("10000");
29 test.check("10001");
30 test.check("20000");
31 }
32 }
// リスト 4-3 の実行例 C:\Home> java SetTest 10000はあります 10001はありません 20000はあります
8行目のコンストラクタで生成されるインスタンスの型は、java.util.Setです。11行目から13行目でオブジェクトを登録し、17行目では引数で指定したオブジェクトが存在するかどうか確かめています。
ArrayListと同じように、HashSetも同期化されていないので、マルチスレッドで使うときには動作が保証されません。同期化するには、リスト4-4のように、java.util.CollectionsクラスのメソッドCollections#synchronizedSet(Set)を使います。
// リスト 4-4
Set newSet = Collections.synchronizedSet(set);
java.util.Setを継承しているインターフェースに、java.util.SortedSetがあります。java.util.SortedSetは、内部でオブジェクトの順番を保持することを保証します。つまりコレクションにオブジェクトの追加や削除を行っても、その中のオブジェクトは自動的に並びかえられます。
java.util.SortedSetを実装しているクラスには、java.util.TreeSetがあります。
Mapは、「キー」と「値」の組合せでオブジェクトが格納されるコレクションです。ちょうど辞書のようなイメージになります。
java.util.Mapはインターフェースであり、これを実装したクラスには
などがあります。これらのクラスはそれぞれ実装方法が異なっており、状況に応じて使い分けることができます。
リスト4-5は、HashMapクラスのインスタンスにあらかじめオブジェクトを登録しておき、指定したキーがコレクションに存在するかどうか確かめ、キーが存在するならそのキーに対応する値を出力するプログラムです。
// リスト 4-5
1 import java.util.Map;
2 import java.util.HashMap;
3
4 public class MapTest {
5
6 private Map map;
7
8 public MapTest() {
9 map = new HashMap();
10 map.put("10000", "福沢諭吉");
11 map.put("5000", "新渡戸稲造");
12 map.put("2000", "紫式部");
13 map.put("1000", "夏目漱石");
14 }
15
16 public void check(String key) {
17 if (map.containsKey(key)) {
18 String value = (String)map.get(key);
19 System.out.print(key);
20 System.out.print("円札は");
21 System.out.print(value);
22 System.out.println("です");
23 } else {
24 System.out.print(key);
25 System.out.println("円札はありません");
26 }
27 }
28
29 public static void main(String[] argv) {
30 MapTest test = new MapTest();
31 test.check("500");
32 test.check("2000");
33 test.check("10000");
34 }
35 }
// リスト 4-5 の実行例 C:\Home> java MapTest 500円札はありません 2000円札は紫式部です 10000円札は福沢諭吉です
9行目のコンストラクタで生成されるインスタンスの型は、java.util.Mapにしています。10行目から13行目でキーと値のペアを登録し、17行目では引数で指定したキーが存在するかどうか確かめています。そして18行目で引数をキーにして値を取り出します。
HashMapもやはり同期化されていないので、マルチスレッドで使うときには動作が保証されません。同期化するには、リスト4-6のようにjava.util.CollectionsクラスのメソッドCollections#synchronizedMap(Map)を使います。
// リスト 4-6
Map newMap = Collections.synchronizedMap(map);
java.util.Mapを継承しているインターフェースに、java.util.SortedMapがあります。java.util.SortedMapは、内部でキーの順番を保持することを保証しています。つまり、コレクションにオブジェクトの追加や削除を行っても、その中のオブジェクトはキーの順序で自動的に並びかえられます。java.util.SortedMapを実装しているクラスには、java.util.TreeMapがあります。
java.util.Hashtableは、Java 2 SDKが登場する前から存在しており、HashMapによく似た機能を持っています。HashMapとは違って、同期化もされています。Java 2 SDK以降でのHashtableは、java.util.Mapインターフェースを実装するように変更されました。
コレクションに含まれているそれぞれのオブジェクトに対して、繰り返しの処理をするには、java.util.Iteratorを使います。図C.4[Iterator]のようなイメージになります。
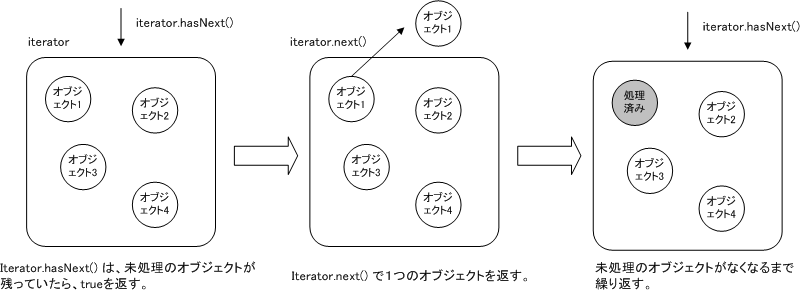
まずは、Iteratorを使ったサンプルを見てみましょう。リスト4-7は、リスト4-1のプログラムに、List型のオブジェクトに格納されたファイルの中身をIteratorを使って出力する機能を加えたものです。
// リスト 4-7
1 import java.util.List;
2 import java.util.ArrayList;
3 import java.util.Iterator;
4 import java.io.FileReader;
5 import java.io.BufferedReader;
6 import java.io.FileNotFoundException;
7 import java.io.IOException;
8
9 public class IteratorTest {
10
11 public List readFile(String fileName) {
12 List list = new ArrayList();
13 try {
14 FileReader file_reader = new FileReader(fileName);
15 BufferedReader buffered_reader = new BufferedReader(file_reader);
16 String line;
17 while ((line = buffered_reader.readLine()) != null) {
18 list.add(line);
19 }
20 } catch (FileNotFoundException fnfe) {
21 fnfe.printStackTrace();
22 } catch (IOException ioe) {
23 ioe.printStackTrace();
24 }
25 return list;
26 }
27
28 public static void main(String[] argv) {
29 IteratorTest test = new IteratorTest();
30 List list = test.readFile(argv[0]);
31 Iterator iterator = list.iterator();
32 while (iterator.hasNext()) {
33 String value = (String)iterator.next();
34 System.out.println(value);
35 }
36 }
37 }
// リスト 4-7 の実行例 C:\Home> java IteratorTest sample.txt java.util.List java.util.Set java.util.Map java.util.SortedSet java.util.SortedMap java.util.Date java.text.DateFormat org.w3c.dom.Node gnu.regexp.RE jp.ac.wakhok.tomoharu.CSVLine
まず31行目でIteratorを取り出します。32行目でまだ処理をしていないオブジェクトが残っているかどうかチェックし、33行目でオブジェクトを1つ取り出しています。
このようにIteratorを使えば、繰り返しのループ処理を簡潔に書けるのです。
また、Iteratorとよく似た機能を持つ、java.util.Enumerationがあります。JDK1.1まではjava.util.Iteratorはなかったので、VectorやHashtableに含まれているオブジェクトの繰り返し処理に使われます。
コレクション・フレームワークでは、ソートやサーチなどの代表的なアルゴリズムを使ってコレクションを操作できます。このためのクラスとして、
の2つがあります。いずれも、ソートやサーチなどの便利な機能をまとめたものです。java.util.Collectionsはコレクションに対して使い、java.util.Arraysは配列に対して使うものです。
リスト4-7の出力結果を、アルファベット順に並べてみましょう。そのためには、リスト4-7のmainメソッドを、リスト4-8のように変更します。
// リスト 4-8
1 public static void main(String[] argv) {
2 IteratorAndSortTest test = new IteratorAndSortTest();
3 List list = test.readFile(argv[0]);
4 Collections.sort(list);
5 Iterator iterator = list.iterator();
6 while (iterator.hasNext()) {
7 String value = (String)iterator.next();
8 System.out.println(value);
9 }
10 }
// リスト 4-8 の実行例 C:\Home> java IteratorAndSortTest sample.txt gnu.regexp.RE java.text.DateFormat java.util.Date java.util.List java.util.Map java.util.Set java.util.SortedMap java.util.SortedSet jp.ac.wakhok.tomoharu.CSVLine org.w3c.dom.Node
リスト4-7とリスト4-8のmainメソッドの違いは、リスト4-8の4行目の部分だけです。ここでは、List型のオブジェクトlistを「自然な順序付け」に従ってソートします。この場合は、アルファベット順にソートしています。ソートの規則を細かく設定する方法もありますが、ここでは省略します。